Kreatywne wykorzystanie pliku robots.txt
Gary Illyes, wieloletni pracownik i analityk firmy Google, od czasu do czasu na swoim Twitterze publikuje sondy, które mają na celu sprawdzić wiedzę obserwujących jego profil specjalistów SEO. Spoglądając na wyniki ostatniej ankiety, która pojawiła się 7 lipca 2020 r., można odnieść wrażenie, że część z nich nadal nie rozumie, jak dokładnie działa robots.txt. Nie będziemy jednak rozważać najczęstszych błędów popełnianych w tym pliku, a skupimy się na zupełnie innych sposobach jego wykorzystania.
Spis treści
Wróćmy jednak do sondy. Pytanie z pozoru jest bardzo proste – jak zachowa się Googlebot, który natrafi na taki zapis w pliku robots.txt?
W zabawie na chwilę obecną wzięło udział ponad 1600 osób. To już wystarczająco duża grupa, aby otrzymane wyniki były miarodajne. I jeśli założyć, że w ankiecie odpowiadały wyłącznie osoby związane z branżą SEO, są one zaskakujące – prawie 40% osób wybrało błędną odpowiedź, uznając że robot Google podąży za bardziej ogólną dyrektywą. Tymczasem aby udzielić poprawnej odpowiedzi wystarczyło pamiętać, że podobnie jak w polskim prawodawstwie, przepis szczególny ma pierwszeństwo stosowania przed przepisem ogólnym.
Pliki robots.txt wskazują robotom wyszukiwarek, które ze stron i plików na nich umieszczonych nie powinny być odwiedzane, a co za tym idzie, indeksowane przez roboty wyszukiwarek. Chroni to stronę m.in. przed nadmiernym przeciążeniem zapytaniami oraz oszczędza tzw. budżet crawlowania. Modyfikacja pliku powinna być zawsze przeprowadzana uważnie, a przed jego wdrożeniem zawsze warto dla pewności przetestować użyte dyrektywy przy pomocy np. Robots Testing Tool w Google Search Console (narzędzie jest dostępne po zalogowaniu się do swojego konta w Google Search Console).
W niniejszym artykule zebraliśmy jednak kilka przykładów wykorzystania plików robots.txt, które poza optymalizacją ruchu robotów, służą też innym celom lub po prostu poprawiają humor przeglądającym je osobom.
Blokuj roboty, nie ułatwiaj życia hakerom
Należy pamiętać, że plik robots.txt służy do blokowania dostępu robotom, a nie do ukrywania zasobów na serwerze przed światem. Jeśli zapomnimy o tej regule, w pliku robots.txt mogą znaleźć się wskazówki odnośnie zawartości, której nie chcielibyśmy ujawniać nie tylko robotom, ale również innym istotom zbudowanym w oparciu o substancje białkowe.
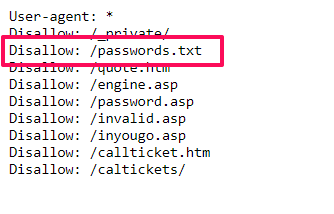
Powyższy przykład, który blokuje dostęp do pliku passwords.txt jest karygodny. Nie tylko z uwagi, że wskazujemy istnienie tego pliku, ale również dlatego, że zawartość takiego pliku nie powinna być w ogóle możliwa do wyświetlenia. Trzymanie haseł w pliku tekstowym na serwerze jest po prostu absolutnie nie do zaakceptowania.
Wsparcie modelu biznesowego
TaoBao to największa platforma e-commerce – obecnie jest ósmą najczęściej odwiedzaną stroną świata. I chociaż działa wyłącznie na rynku chińskim, w pliku robots.txt blokuje całkowicie dostęp robotom miejscowej wyszukiwarki Baidu.
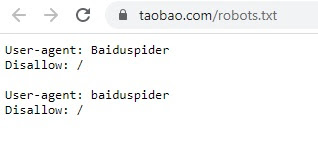
Na pierwszy rzut oka można uznać to za strzał w stopę. W rzeczywistości jednak rezygnacja platformy TaoBao z ruchu z Baidu zwiększa zyski holdingu Alibaba Group. Paradoks? Otóż nie. Głównym źródłem dochodów Alibaba Group z platformy TaoBao (a także ich siostrzanej strony Tmall, który również blokuje robota Baidu), są zyski z reklam PPC. Kiedy zatem klient szuka w Taobao produktu, obok standardowych rezultatów wyszukiwania platforma wyświetla również reklamy od sprzedawców. Tym samym umożliwienie znalezienia produktu z poziomu Baidu zmniejszyłoby prawdopodobieństwo kliknięcia w reklamę, a więc i zyski holdingu. Wykorzystanie pliku robots.txt jako wsparcie modelu biznesowego właściciela TaoBao sprawdza się jednak tylko dlatego, że platforma ta ma ugruntowaną pozycję na rynku chińskim i wiele wskazuje na to, że jeszcze przez lata jej nie straci.
Szukasz pracy? Czytaj pliki robots.txt
Pliki robots.txt powstały dla robotów wyszukiwarek, ale webmasterzy wielu stron są świadomi, że zaglądają na nie także specjaliści SEO. Dlaczego to robią? Prawdopodobnie z czystej z ciekawości lub z chęci sprawdzenia, jak takimi plikami zarządzają największe marki świata. Niektóre z nich, wykorzystują ten fakt do przeprowadzenia rekrutacji – zaproszenie do aplikowania o pracę znajdują się m.in. w plikach robots.txt takich stron jak:
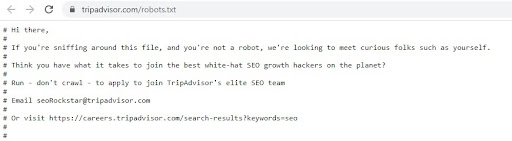
TripAdvisor.com
Nvidia.com
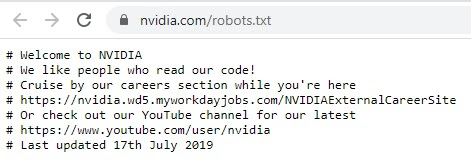
Wayfair.com
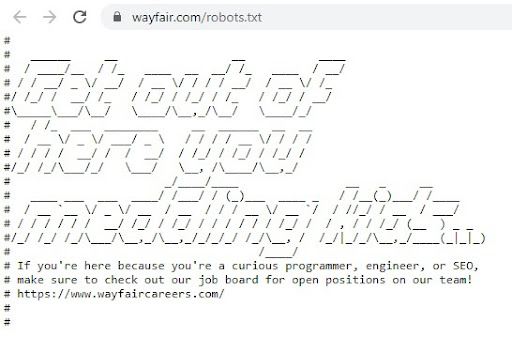
Pinterest.com

SeerInteractive.com
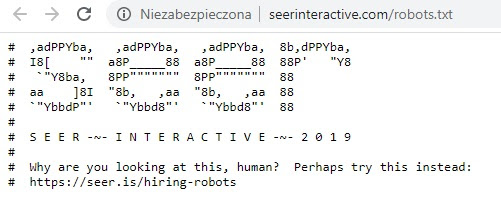
Google także rekrutuje w podobny sposób. Zaproszenie do sprawdzenia ofert pracy znajduje się jednak w pliku… humans.txt!
Google.com

Uratujmy świat przed robotami!
To, że ludzkość prędzej czy później upadnie i władzę nad światem przejmą roboty, jest nieuniknione. Póki jednak badania nad AI jeszcze trwają, wciąż mamy szansę. Twórcy kilku stron postanowili stanąć na pierwszej liniii obrony i w plikach robots.txt przemyciło dyrektywy, które mogą ochronić homo sapiens przed robo-supremacją.
Jak najlepiej powstrzymać robota przed wyrządzeniem krzywdy człowiekowi? Oczywiście nakazać mu przestrzegać Trzech praw robotyki Asimova. Na ten krok zdecydowali się m.in. webmasterzy Yelp.com, Last.fm i Nest.com.
Yelp.com

Last.fm
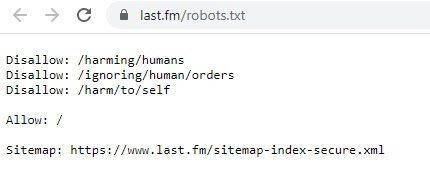
Nest.com
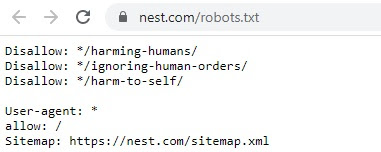
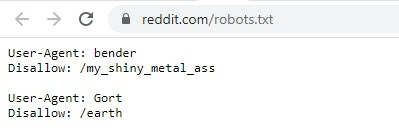
Reddit uznał natomiast, że tylko dwie cybernetyczne jednostki są dla ludzi prawdziwym zagrożeniem. Dlatego postanowił bronić naszą planetę przed Gortem, metalowym bodyguardem kosmity Klaatu z kultowego filmu “Dzień w którym zatrzymała się Ziemia” oraz przed Benderem, niepoprawnym politycznie robotem z “Futuramy”, który nie potrafi trzymać języka za zębami i wszystkim każe gryźć się… no wiecie gdzie.
Reddit.com
Z kolei YouTube.com, nawiązując do popularnej piosenki “Robots” nowozelandzkiego zespołu Flight Of The Conchords, wprost przyznaje, że ich strona powstała w alternatywnej linii czasu, w której ludzkość ostatecznie przegrała.
Youtube.com

A co jeśli nie wszyscy zasługują na ocalenie? W 2015 r. z okazji 20-tych urodzin pliku robots.txt Google postanowiła dodać do swojej strony plik killer-robots.txt, a w nim kilka linijek tekstu, który miał powstrzymać T-800 i T-1000 przed likwidacją tylko i wyłącznie Larry’ego Page’a i Sergey’a Brina. Być może zdjęcie z witryny tego pliku było błędem, bo jak wiadomo SkyNet istnieje, bazuje w Chinach i zna już dobrze twarze kilkuset milionów osób, a więc niewykluczone, że ma także w bazie wizerunek współtwórców Google.
Co jeszcze można znaleźć w plikach robots.txt?
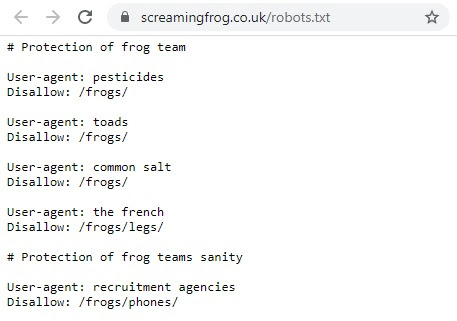
ScreamingFrog.com, twórca narzędzia, z którego korzystamy na co dzień w naszej pracy, blokuje dostęp do swojej żabiej ekipy wszystkiemu i wszystkim zagrażającym ich życiu, a więc pestycydom, ropuchom, soli kuchennej i Francuzom. Nie pomija również agencji rekrutacyjnych.
ScreamingFrog.co.uk
Nike.com z kolei zachęca roboty do żwawego biegania po swojej stronie, modyfikując specjalnie dla nich swoje hasło reklamowe “Just do it!”
Nike.com

Discord.com mrugnął zaś okiem do NSA, czyli Agencji Bezpieczeństwa Krajowego Stanów Zjednoczonych Ameryki Północnej, blokując dostęp do swojej strony ich “agentom”, co oczywiście jest nawiązaniem do faktu, że NSA masowo gromadzi i przetwarza prywatne dane zebrane w trakcie odsłuchiwania rozmów i czytania korespondencji obywateli U.S.A. (i nie tylko).
Discord.com

To tylko niektóre tzw. “easter eggs” ukryte w plikach robots.txt popularnych witryn. Zapewne gdyby pogrzebać głębiej, na światło dzienne wypłynęłoby jeszcze więcej dowodów, że specjaliści zajmujący się tworzeniem stron internetowych, potrafią kreatywnie i zarazem z humorem wykorzystać ten plik. W 2010 roku właściciele strony Whyte and Mackay ukryli w nim nawet butelkę 30-letniej whisky!
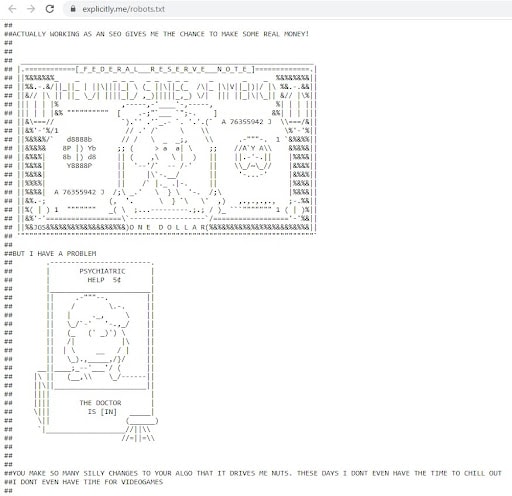
Na koniec jednak zostawiam was z długim listem, jaki za pośrednictwem pliku robots.txt skierował do Google seowiec Rishi Lakhani, wylewając poniekąd swoją frustrację na ciągłe zmiany jego algorytmu. Pełna treść znajduje się tutaj.
Explicilty.com